
Semantic Linking: Managing Mappings
How to stay connected

In the last article, I wrote about the concept of “aboutness”. It was an argument for separating the data object (table, column, view, file…) from the semantic object (term, concept…) and connecting the two. This connection, of course, is a mapping between objects on the Data Plane and objects on the Knowledge Plane: a statement that “A is about B”.

While you might now (hopefully) agree with me that each kind of object lives on its own plane and we don’t mix data and semantics, we need to answer one question that wasn’t covered in the last piece: what about the mapping itself?
As Juan Sequeda mentioned in a LinkedIn discussion:
the mapping itself is a first class object
so it seems prudent for us to consider how these first-class objects should be managed!
Where does the mapping live?
In my earlier article on Semantic Architecture, I divided the world in two layers, the Data Plane and the Knowledge Plane. Data objects live on the Data Plane, all the semantics live on the Knowledge Plane.

But the mapping also needs to live somewhere, we can’t leave it homeless! Let’s briefly consider what are our options.
Option 1. Mappings are properties on the Data Plane
We established previously that maintaining all your semantical information as labels on the Data Plane is a bad idea and we should all feel bad about implementing something silly like that1. But what if we used the metadata capabilities of the Data Plane for just the link?
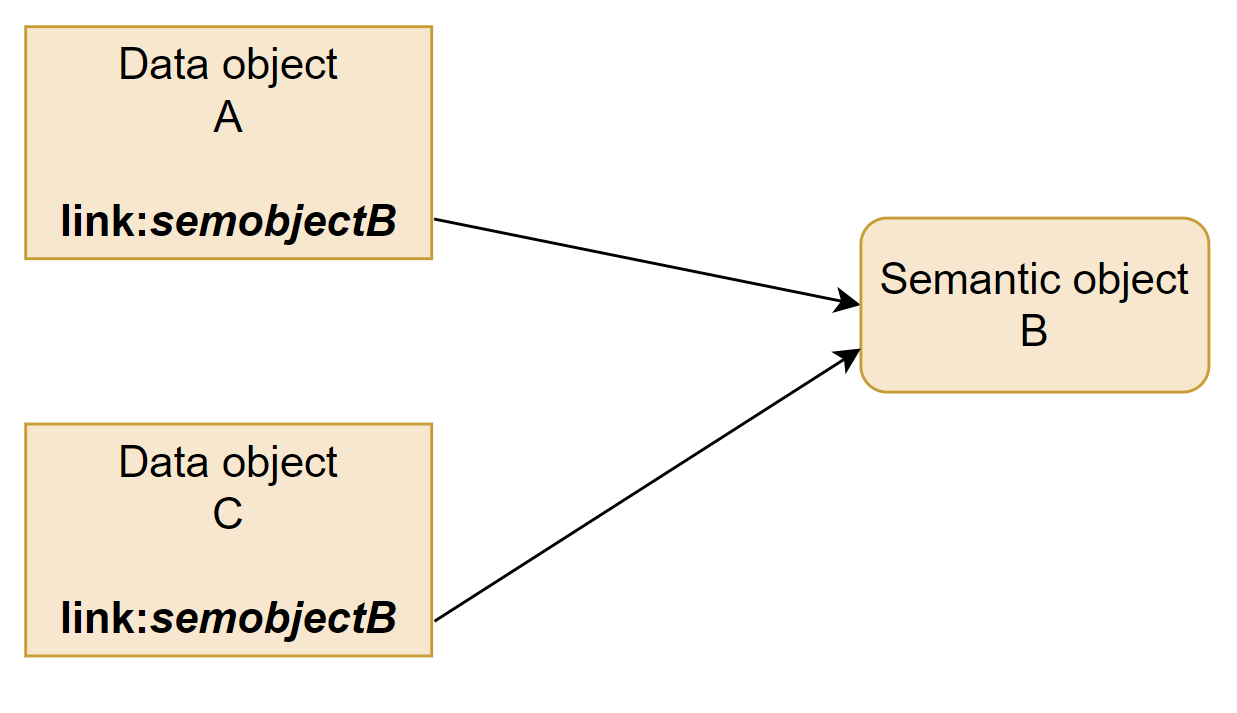
We could certainly conceive of, and in many cases rather easily implement, a solution where a property is added to the data object that contains an explicit link to the semantic object. This could be a unique identifier of any kind - following the semantic web standards, we would probably be using something like a URI (Uniform Resource Identifier).
Technically, this works. The separation of the layers is maintained: we are not keeping information about the semantic object within the Data Plane, it’s just the link. The definition of the term B itself still lives where it should, on the Knowledge Plane. It’s possible for any user of the data (human or AI) to follow the link and understand the aboutness of the data object. And two data objects (A and C in our diagram above) can refer to the exact same semantic object, thus making the Knowledge Plane reusable and enabling interesting semantic “integration” situations.
But this makes it a bit awkward to actually find the data you need! If the user approaches the Knowledge Plane first (which is exactly what AI agents will do in this kind of a setup), they don’t have a clear path to the Data Plane. The connection only exists from Data Plane to Knowledge Plane, not the other way.
Well, what if we maintain the links within both objects, you say? Technically possible, sure. But now we’re starting to repeat information. We would need to maintain the exact same piece of information (the link connecting A and B) both within the Data Plane and within the Knowledge Plane. Will these two instances stay in sync? Or will they start drifting apart? Perhaps eventually A points to B, but B points only to C? Sure, we could then build quality checks and guardrails… but it starts to sound like a bit too much hassle. No; perhaps forcing the links to be properties of the data objects (and/or semantic objects) is not a very good idea after all2.
Option 2. Mappings live on their own between the Planes
How about we actually treat the mapping as the first-class citizen it is? Instead of a property of a thing, maybe it can be a thing of its own?
And as a first-class citizen, maybe it’s deserving of a plane of its own, too?
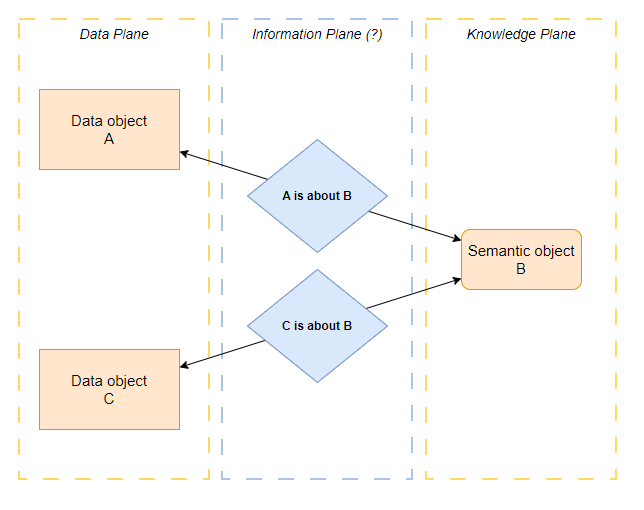
Andrea Gioia, whose conceptualizations of Data Plane and Knowledge Plane I’ve used liberally here and in my earlier articles, calls this layer the Information Plane3.
What this mapping object looks like from a technical viewpoint is interesting but also a rabbithole I don’t want to get into now. Suffice to say, solutions and standards exist (see e.g. Relational to RDF Mapping Language). Some of them are quite complex (see e.g. the preceding link - phew!).
Whatever the format of the mapping, it needs to be physically maintained somewhere. It feels a bit weird to me to even consider a wholly separate technology just to maintain mappings between the Data Plane and the Knowledge Plane (though given the extreme fragmentation of the Modern Data Stack era, I’m sure vendors specializing in precisely this probably already exist).
If we take it in very simple terms, the requirements for an implementation of this Information Plane are:
Visibility to both the Data Plane and the Knowledge Plane
Capability to create mappings between objects on the two planes
Accessibility to users coming from either the Data Plane or the Knowledge Plane so that they can easily discover mappings of any object of interest
You would think this is something that data catalogs excel in. But when I type “Customer” in the search bar of most data catalog tools, I tend to get between 257 and 18 462 results of tables, schemas, columns, and dashboards that have the string ‘CUST’ somewhere in their name!
While this kind of mapping information can often be managed in a data catalog tool, the separation of these three layers is not usually very clear. The different ways a user can approach the catalog (i.e. which layer comes up first) tend not to be properly covered, and the catalog tools’ original sin - building everything around the Data Plane and simply glueing all the other stuff around it - is all too evident in the user experience.4
Option 3. Mappings are part of the (extended) Knowledge Plane
The Knowledge Plane is usually (with very good reason) imagined and implemented as a knowledge graph. A knowledge graph is an implementation of a formal ontology, made of triples (subject-predicate-object). A triple might look like this:
Customer - makes - Order
where “Customer” and “Order” are semantic objects, namely concepts or terms, and “makes” is the relationship between them (of course, the exact format of this information depends on the implemented standard, but this is the basic idea).
Let’s go back to the beginning. What was this whole “aboutness” business about in the first place? Yes, we wanted to state that “data object A is about semantic object B”.
Now wait a minute… Are your pattern-matching senses tingling like mine?5
Data object A - is about - semantic object B
It’s a triple!
What if we were to extend the Knowledge Plane so that it not only contains the semantic objects (terms, concepts, their definitions, and relations between them), but also knowledge about what exists on the Data Plane?
The data objects themselves of course need to live on their own plane, but nothing prevents us from adding representations of the data objects into the Knowledge Plane. This would result in the Knowledge Plane containing the semantic object, a representation of the data object, and the linking between them, all as natural parts of the overall graph.
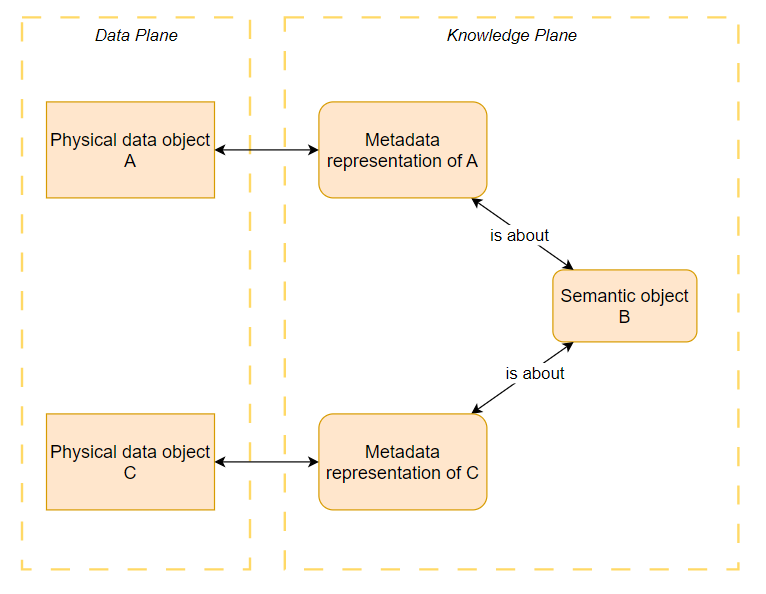
In effect, we are now extending the graph so that the metadata representations of the data objects are “hanging” from the semantic objects. And because there must always be a 1:1 match between the physical data object (that still lives on the Data Plane) and its metadata representation, the link can be easily traversed both ways.
In a way, this is precisely what most data catalogs purport to do: they connect to the Data Plane, read the metadata of the objects therein, and bring those metadata representations into the catalog where they can be, well, catalogued. This 1:1 representation of the contents of the Data Plane can be easily built in most data catalog tools.
The problem of the data catalog approach is that they are really, really bad at managing the rest of the Knowledge Plane! The whole idea of the Knowledge Plane is to maintain information about the semantic objects and their interrelations, and now we just want to extend it to also include representations of the data objects so that we can deal with the pesky problem of semantic linking between the planes. But most catalogs only offer flat “Business Glossary” lists as if it was an afterthought6 - you can’t even document the statement “Customer makes an Order” in most catalog tools, as the business terms can’t be connected with each other!
Luckily, some catalog vendors are starting to see the light. They are talking about “context” in much more general terms than previously. However, when the starting point is “technical metadata is what we do”, I’m afraid the path to full-fledged Knowledge Plane management is not going to be easy nor straightforward.
Regardless, I personally think this is the only feasible path for solving semantic linking for good.
Closing thoughts on semantic linking
These two articles on semantic linking hopefully explained how I see the question of connecting physical data with its semantic meaning. I mentioned in my original Semantic Architecture article that everything is in flux and solutions are being developed, but that no best-practices stack seems to have emerged yet. This very much holds true for the semantic linking part of the overall architecture.
Encouragingly, I have recently observed and been involved in teams building such links. While not all the tooling is quite there yet, there are very clever people able to twist the bits and pieces we have now into something that at least gets us forward. The problem isn’t that managing semantics and semantic linking is technically impossible - it’s certainly doable, even though some solutions might be a bit hacky right now! It’s more that the big-picture architectural thinking around semantics is lacking in many organizations (tool vendors included). The problems start at very basic level, at separating the data object from its semantics, and then connecting the two. Unless we get our thinking in these super basic concepts organized, we’ll be stuck in siloed solution-level micromanagement hell forever.
If you find these little articles helping with your thinking, consider subscribing - there’s more to come! And if you find them helping with your colleagues’ thinking, consider sharing!
Thank you for reading, and until next time - cheerio!
Yes I also feel bad about having done that. It’s our shared shame!
Of course, while maintaining the link as a property is not necessarily a super good idea, we must remember it’s still a lot better than maintaining the actual semantics as a property! I would expect many organizations to choose this option initially as an easy-ish solution, and then eventually to switch to options 2 or 3 when they realize it’s causing them issues.
There’s more to all of these concepts in Andrea’s writing - I heartily recommend following him and watching his presentations wherever you can!
The whole question of “What next for data catalogs” or, perhaps, “How to fix data catalogs” deserves an article of its own, I think - the issue needs to be covered in this article to some degree because the solution match seems obvious at first glance, but the answers require further elaboration. Perhaps I’ll add that to the list!
Pattern-matching is a powerful capability of the human mind. A good data modeler has excellent pattern-matching skills, often manifesting as the capability to almost intuitively reuse bits and pieces of models (“oh this is the Party pattern again”). LLMs are pattern-matching machines for human language. I find this professionally and philosophically interesting. Of course, one must also remember that overstimulated pattern-matching in humans is usually called schizophrenia. How that relates to the behaviours observed in LLMs, or indeed in some data modelers, I’ll leave for you to think about.
Which, for most catalog vendors, it was.
Big brain article 💪
Great piece again.
I found one of the most interesting aspects your requirement for the Information Plane:
"Accessibility to users coming from either the Data Plane or the Knowledge Plane so that they can easily discover mappings of any object of interest"
That is eventually what it boils down to for me; the fashion in which the relation is stored is more of a practical consideration and for a big part dependent on what capabilities are offered through tools and technologies. The proof of the pudding is how and how well this information (or knowledge, depending on the plane ;) ) can actually be consumed by users and how they generate their business value from it