
Semantic Linking: the Aboutness of Data
Connecting the layers of Semantic Architecture

Having data without semantics means you’re flying blind. Having semantics without data means you don’t have a plane to fly. The combination is what we’re after - and how that combination is achieved is the subject of today’s article.
I wrote earlier about “Semantic Architecture”; if you haven’t, you might want to read that, so that it’s easier to place this article in its rightful context.

But let me re-iterate the basic idea here:
“Data Plane” is where all our data lives in. This is all the technological components that contain data: tables, views, files, interfaces, you name it.
“Knowledge Plane” is where semantics lives in. Semantics is, at its core, terms and definitions, and relationships between terms.
The two planes must be managed separately (for reasons that we will touch upon today), and they absolutely must be connected to each other (which is today’s topic).
The whole big picture described in the above article looks like this:
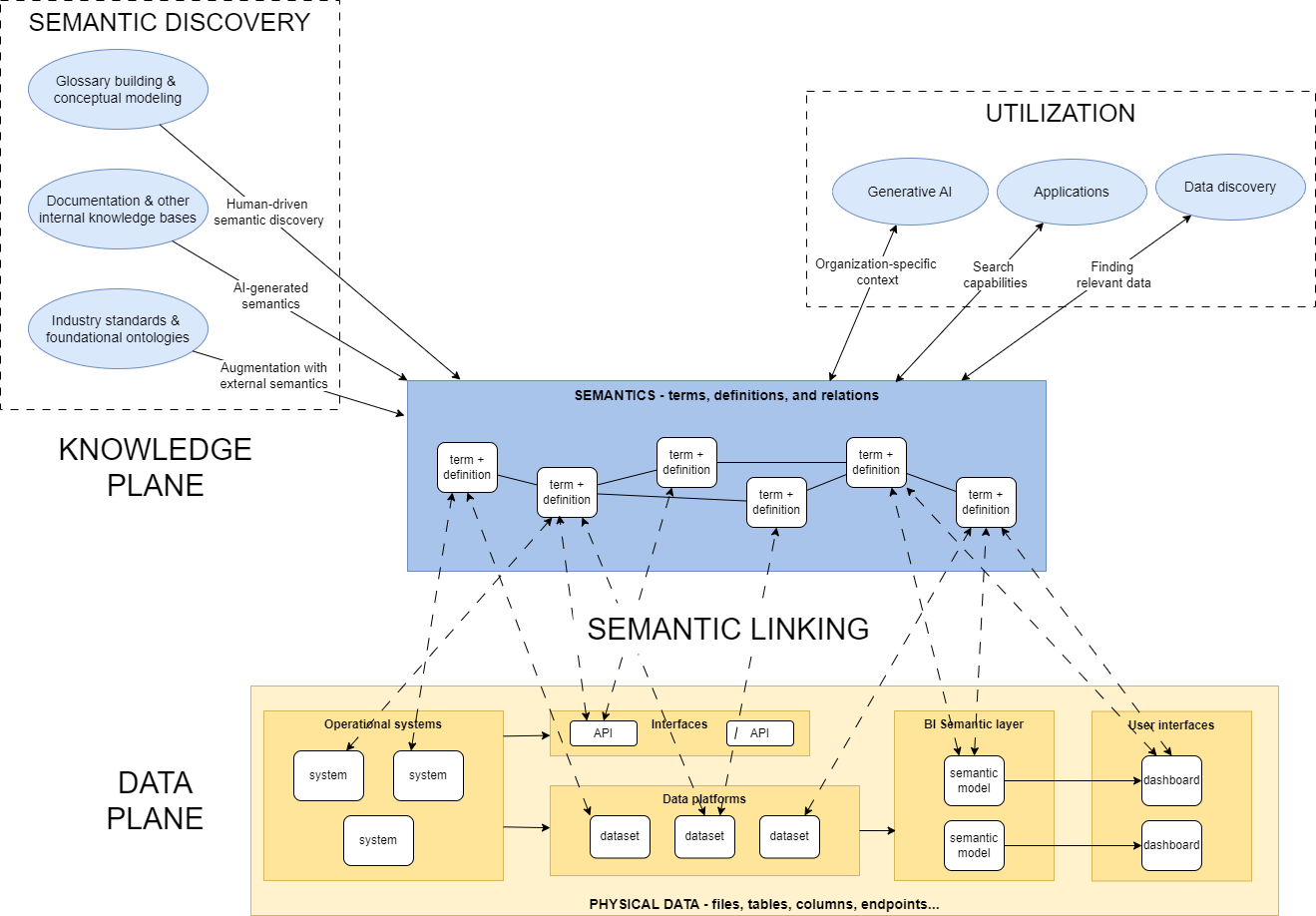
The focus today is in the connection between the two planes.
I called this connection “Semantic Linking”. Tongue firmly in cheek (or so I thought), I suggested that this could also be called the “isaboutness” of data. Turns out, aboutness is an actual term from Library & Information Sciences that describes precisely this - as John O’Gorman and Jessica Talisman kindly informed me in a LinkedIn discussion! So in a way, today’s article is about aboutness1. I want to have a very simple look at the basic concepts of connecting data and meaning based on the overall idea of separate Data and Knowledge Planes.
What is the data about?
It has always been a source of some amusement (and occasional bemusement) to me that on average, us data people are really bad at answering the question “what is this data about”. Sure, we can talk endlessly about its technical lineage and transformations done to it and the source system data object from which it originally came from, but none of that answers the question. And if you don’t know what the data you’re working with means, then do you really know what you’re doing?2
This question of aboutness is at the very core of managing semantics, so it’s worthwhile to break it down a bit.
Let’s consider a very simple setup. We have one data object, A, on our Data Plane. The data object can be anything - a table, a view, a column. We also have one “semantic object” - i.e. a term with its definition - on our Knowledge Plane. The “aboutness” of the data object is the semantic link between A and B:
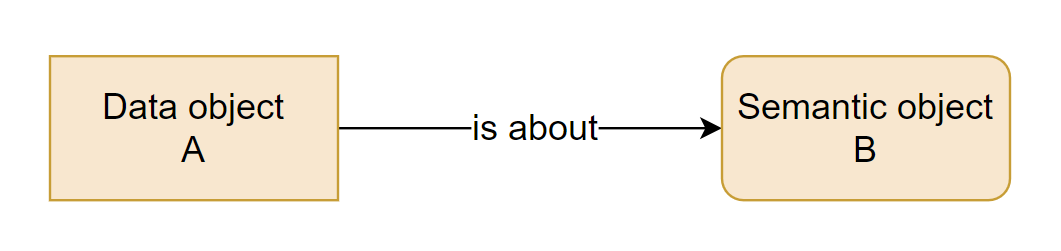
The vitally important thing to understand is that this is NOT “data lineage” in the sense that data would flow from A to B! The semantic object B is not some kind of a data storage object into which we move the actual numbers from A. Data itself doesn’t move anywhere; this is purely a connection at metadata level. In effect, we just want to be able to state that “A is about B” - e.g. “mydb.dim_customer is about Active Customers” or “clv_estimate is about Customer Lifetime Value”.
Equally important is to understand that it must be a connection.
“Aboutness” is a link, not a property
A common mistake many data teams currently make when figuring out semantics is to consider semantical information to be a part of the data object.
Many technology platforms allow you to add labels or descriptions to your data objects. This is what happens in those “BI Semantic Layer” technologies (like Looker or PowerBI), but increasingly it is also a feature of many data platforms (like BigQuery or Snowflake).
For a technically-oriented person, this might feel like an obvious solution: if we need to state that “A is about B”, why not just add this extra piece of information into A itself? Add a little free-text field that can be accessed when someone is reading the data from A, and hey presto - semantics!
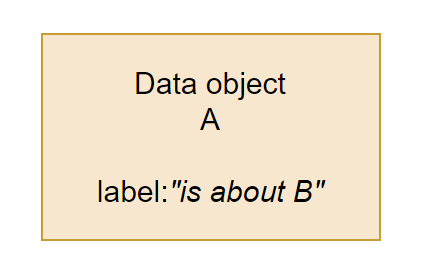
This might be enough to document this particular data object in this particular solution. Humans or AI, when accessing the data object A, can see what it means, and everyone is happy!
That is, they are happy as long as this is the only data object you will ever have.
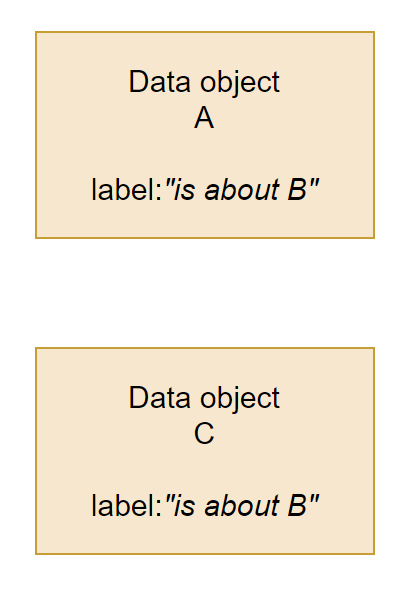
If you happen to have a data object C, which also happens to be about the semantic concept B, you of course need to have both of them labeled. Perhaps, if you only ever have these two data objects, this will be fine too: if something changes somewhere, you can update both labels accordingly. But perhaps A and C are created and maintained by different teams? Perhaps those teams don’t know about each other? Perhaps they don’t actually have a shared definition of the semantic concept B? Perhaps someone just typoed the free-text label? And, perhaps, there are not just two but eleven thousand data objects.
Think now of an AI agent (or better yet, a hapless human!) approaching your data landscape with the following thought: “I need to find information that tells me about B”. Yes, they will come at you with the semantic object in mind - after all, natural language is how we use GenAI!
How many different labels will there be? How many of those labels will refer to the semantic concept B, even if they actually are about B? How many of those labels will refer to the semantic concept B, even if they actually aren’t about B?
Managing semantics based on object-level free-text labels is simply not feasible beyond single-solution scope3. At best, the result is a million little semantic siloes. At worst, it’s an incomprehensible mess that just makes everything worse. The only scalable (and “AI-ready”) option is to consider the data objects and semantic objects separately, and to build mappings between them:
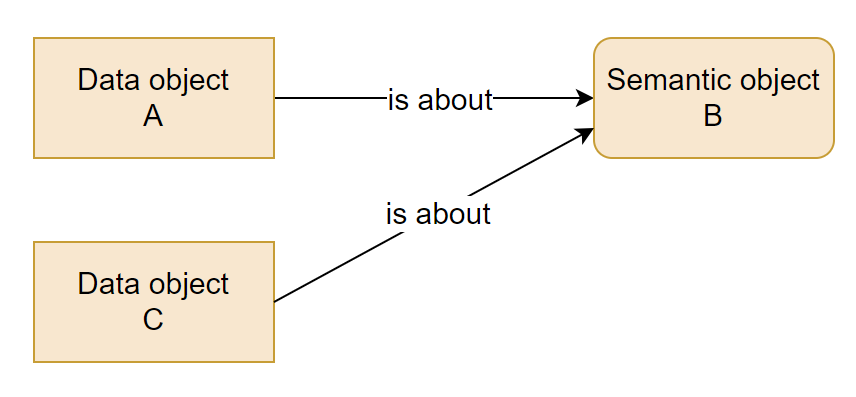
When the data objects and the semantic objects are 1. separated and 2. connected, there is much less to maintain. Whatever the definition of B is, it’s defined just once. This makes the Knowledge Plane infinitely reusable.
In my earlier article on Semantic Architecture, I mentioned that the separation between these two planes - Data and Knowledge - is a must. You should also read Juan Sequeda’s excellent recent LinkedIn posts on this separation and the mappings4 between the planes. .
Without the separation, we’re stuck in a labeling hell inside the Data Plane. Without the mappings, the Knowledge Plane is pointless.
Semantic Linking is data integration (in a way!)
If we have built our Knowledge Layer smartly so that it contains not just terms and definitions but also relationships between terms, and our Semantic Linking is done correctly, another interesting benefit appears.
Consider now that our simple structure has two other objects: data object D, and another semantic object E. D is about E, but we also have an extra piece of information: the two semantic objects are related to each other.
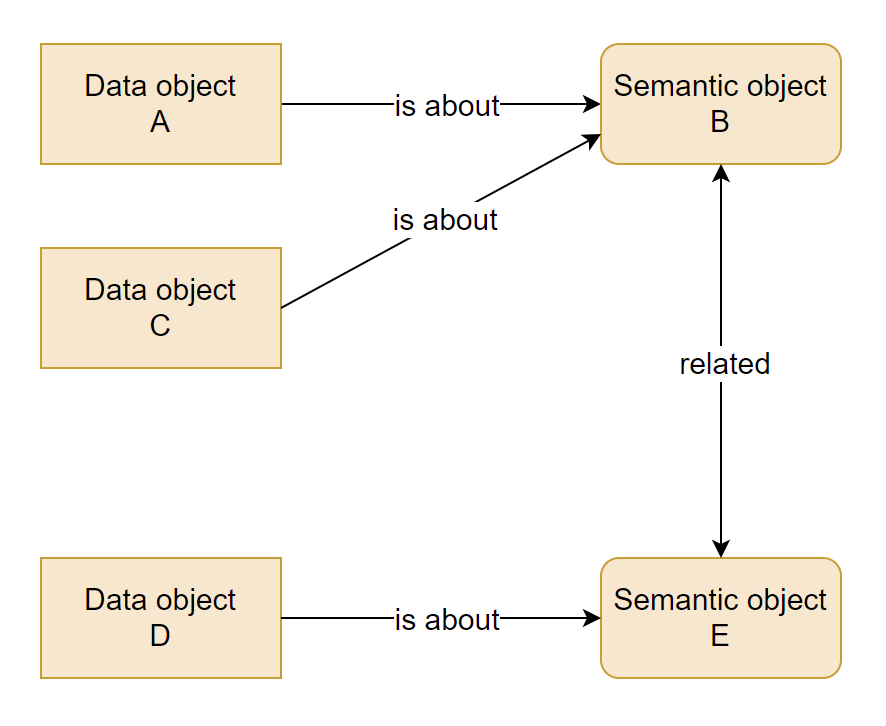
Now, of course in a really smartly built Knowledge Plane, we would have also properly named the relation between B and E - the relation itself would carry some semantical meaning, like “Customer may cancel an Order”5. But for the purposes of our generic example, just knowing that the two semantic concepts are related is enough.
What does this tell us about the data objects? I have written about data integration a couple of times in this blog. In those articles, I was mainly talking about physical integration of the actual data - i.e. creating a new data structure in which two or more data objects are merged together. But with Semantic Linking and Knowledge Plane in place, we have another way of connecting data objects.
We can determine from our setup that the data object D must be related to the data objects A and C. Not because they have a technical connection (like a foreign key relationship or something like that), but because they are semantically connected via the relationship between B and E.
Of course, the usefulness of such a “semantic integration” depends a lot on the level of detail of our semantic objects and their relationship (knowing that “Customer Management” has something to do with “Sales” doesn’t help much, but knowing that “Sell-to Customer” is a type of “Customer” might be much more useful). But it’s certainly something we shouldn’t ignore especially with how we now expect AI agents to crawl around our Data Plane. They can be pointed to the right direction via the Knowledge Plane, and Semantic Linking ensures that they find their way to the actual data.
Mappings as metadata
You hopefully now agree with me that the semantical information itself can’t live inside the data object, on the Data Plane.
However, what we didn’t figure out here was where the mapping itself lives. The mapping information is in itself a vital part of Semantic Architecture. Just like we need to maintain not just the semantic objects but also their relations on the Knowledge Plane, we need to maintain the mappings between the data objects and the semantic objects. But where, and how?
This I will cover in the next article! So until then, consider subscribing (to be notified of when that comes out), and cheerio!
The learning curve on knowledge management and semantics is pretty steep, and there’s a whole bunch of us data people climbing it right now. My approach is to read a lot of stuff, try to organize my thoughts in a way that makes sense to me, and then write about it. This has two consequences: first, writing helps me think more clearly. Second, I’m lucky to have some kind and smart people around me who read my writings and let me know whether the conceptualizations I’ve ended up with are sensible or not. Occasionally, I seem to stumble into a concept that already exists (such as “aboutness”). In a way, that makes me happy - I figured out an actual thing, therefore my thinking process must be somewhat correct! On the other hand, it also feels a little silly to “discover” something that the experts already had figured out a long time ago. But at least this way I properly internalize these things - and, based on the feedback I’m getting, every now and then following my thinking process seems to be helpful to others as well, which is great!
Many years ago, when I was leading a project team of younger data engineers (who weren’t called data engineers back then), I used to randomly ask them “what does one row in this table represent” to test if they had really understood the assignment or if they were just blindly writing code according to specs. Nowadays, as a consultant, I do this a lot when I’m genuinely trying to understand the existing solution - but the answers are still a good data point when figuring out the level of maturity in the data team.
One of the most irritating aspects of the whole data & analytics business is that we are so often stuck at single-solution thinking. Sometimes it feels like one has to drag people kicking and screaming from solution level to see the bigger picture. I suppose this whole Substack of mine is an attempt at that!
Juan also mentiones some standards that exist for these mappings, like R2RML (Relational to RDF Mapping Language). But for our purposes here, it’s more important to focus just on the fact that the mapping exists - just know that implementations and solutions exist out there!
Yep, that’s a triple for those of you who are into the RDF/OWL/etc semantic web stack. But that’s not the point today.
Great article!
One major benefit of having a shared semantic object (that holds the common definition) linked to multiple data objects is that it allows classification based on what something is, rather than how it is used or processed in a specific context.
Privacy classification is a good example. Whether something is a direct personal identifier should be determined by its inherent nature, not by how it happens to be used in a particular system. By defining that classification once at the semantic-object level, you can automatically propagate it to all linked data objects.
If policies change, you only need to update the classification in one place, and the change then flows consistently across all connected data assets.
It also makes it much easier to answer questions like, “Where do we store PII?”, and to provide clear evidence based on the semantic relationships.
I don’t think we’ve fully explored all the applications and possibilities that come from linking shared semantic objects to multiple data objects.
Really nice article, Juha. One of the goals in the aboutness approach is to minimize or remove bias in how we describe things as well.