
Why the "Semantic Layer" Isn't Enough for AI
Solution-level siloes and object-level descriptions aren't cutting it

AI needs context, and the most important context is SEMANTICS: what do words mean, and by extension, what does our data mean? As this is now generally accepted to be an absolutely crucial thing in the data & AI industry, a myriad technological solutions are promising to build a “universal semantic layer” in which your crucial metrics definitions live. This universal semantic layer then acts as the entry point for your endless hordes of AI agents: blind automatons desperately trying to come up with a satisfying answer to a human’s poorly defined prompt1, who upon finding their footing on this well-defined and organized universal semantic layer will breathe a digital sigh of relief: “oh thank the machine-gods, that is Customer Lifetime Value!”
There’s a couple of tiny problems with how things currently are set up, though:
First, the “universal semantic layer” is nowhere near universal.
Second, the “universal semantic layer” is hardly semantic at all.
I’m seeing a lot of activity in this layer - lots of engineering projects, and enormous amounts of sales activities - and it seems to me that some of the hopes being put in the “Semantic Layers” are built on a shaky ground. This article is, on one hand, my word of caution: I see teams rushing to develop solutions that I don’t think will scale. A spaghettified future awaits many of us, I’m afraid! On the other hand, I want to cover the descriptive part (what is) before, in a follow-up article, going into the my prescriptive thoughts (what will be, or at least should be).
The “Semantic Layer” as it was (and is)
We’ll start with what we have at hand today.
A great deal of confusion and noise is currently being generated around a concept called “Semantic Layer”. The concept itself is, of course, not a new invention at all: the old BI hands will remember Business Objects and all the equivalent technologies that already appeared decades ago (I think I joined the circus during the SSAS era).
The core idea of the “Semantic Layer”2 in very simple terms is, and has been, the following:
Take data out of your Data Warehouse or equivalent and restructure it so that it better matches a business need.
Add descriptions to various columns and measurements so that people know what things mean.
Then you build your reports and dashboards on top of it. Preferably, the technological format of these “semantic models” is such that it makes it really easy and efficient to build the dashboards with the vendor’s own tools, while at the same time it’s of course possible to build the dashboards with some other vendor’s tool (so that you can claim compatibility) but it’s also a gigantic pain-in-the-butt to do so (so that no-one in their right mind would actually do that at a meaningful scale).
Descriptions, of course, are important semantic content in such a semantic model, but even though it is less obvious, so is the restructuring of data. The data models used in this “Semantic Layer” have often been remodeled so that the data objects (tables, views) more closely match with business objects (Customer, Order, Product), to make the data easier for report builders and BI developers to utilize. Quite often, the chosen model shape in these solutions has been a dimensional model (also known as a star schema) - this has been the go-to solution to a degree that you sometimes run into people who think that “semantic model” actually means facts and dimensions!3
In the latest “Semantic Layer” iterations, the shape of the data model has been viewed as less important. More emphasis has been put on the descriptions, especially metrics definitions (in essence, calculation logic written down), and machine-readability so that our new AI solutions can make sense of the solution and its metadata (consider e.g. LookML as a solution for this).
Overall, this type of “Semantic Layer” could be also described as a “BI Semantic Layer” - it’s intended to be an access point to data, where data is neatly organized and described so that its consumers know what they’re consuming. It originated from the need to build datasets for fast aggregation and calculation underneath fancy dashboards, and it has been evolving into a kind of an universal access layer where we are hoping our AI agents would know which data is what.
However, there are those two tiny problems I mentioned in the intro.
The Silo Layer
All those descriptions and definitions, as neatly as they might be included in the machine-readable structure of the tables and views and columns, purely exist at the level of the technical object. You have a “Customer Lifetime Value” metric in your semantic model, perhaps defined something like this4:
measure: customer_lifetime_value {
type: sum
sql: ${sale_price} ;;
description: "The total sum of revenue we have earned from a single customer throughout the duration of the relationship. Represents long-term value over single transactions."
value_format_name: usd
drill_fields: [user_id, order_id, sale_price]
}Great! That’s semantics!
The metric has been defined, yes. At the level of this individual solution, we’re good.
However, how this usually goes with these tools is that you have now defined a single metric object within a single solution. Sure, it might be that you’re able to utilize the same metric definition in another model within the same project, or within the workspace, or whatever technical container your “Semantic Layer” is divided into.
But six months later, in a neighbouring team, someone else builds another solution in a different project or workspace or whatever, and there they define the following metric:
measure: customer_lifetime_value {
type: sum
sql: ${sales_estimate} ;;
description: "The total sum of expected revenue we are estimating from a single customer throughout the expected duration of the relationship. Represents long-term value over various product groups."
value_format_name: eur
drill_fields: [user_id, productgroup_id, sales_estimate]
}Great! That’s more semantics!
And yet three months after that, someone else using a completely different tool defines Customer Lifetime Value for their solution5:
Customer Lifetime Value =
VAR CLV = DIVIDE(AverageOrderValue * PurchaseFrequency, ChurnRate, 0)
RETURN
IF(ChurnRate = 0, BLANK(), CLV)Great…?
Most “Semantic Layer” implementations today are building semantic siloes. You will end up with multiple solution-level definitions of Customer Lifetime Value. The way things are now, there is no guarantee whatsoever that between teams, solution spaces, and tools, the semantic content will be in any way or form synchronized.
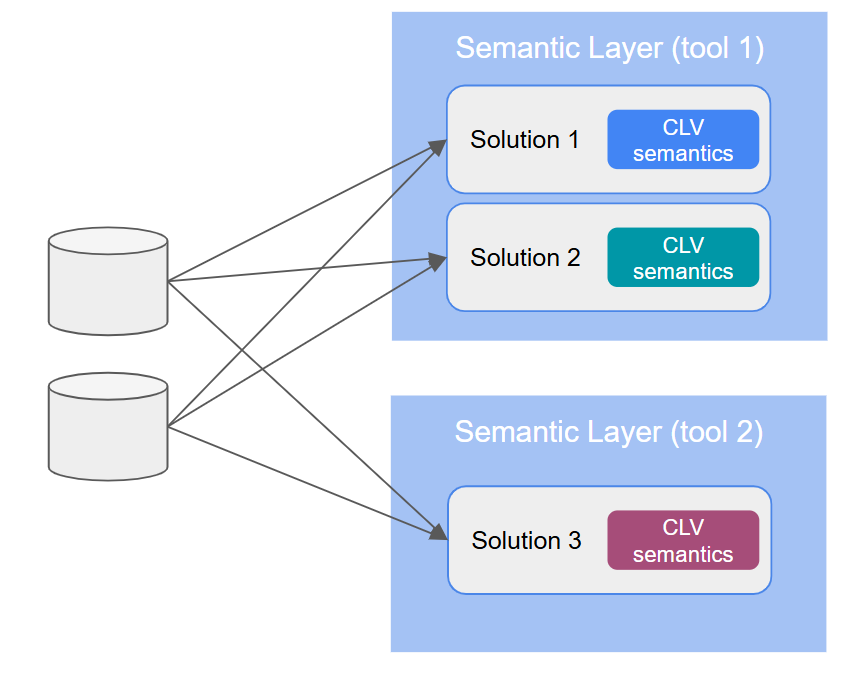
Solution-level semantic siloes are an enormous problem that is not being talked about enough. This will come back to bite everyone in the butt in the coming months and years. How do you expect an AI agent to know which solution to go for? Even if the vendor promises that within their platform, everything will be “universally” defined and reusable, that promise means nothing when considering semantics between platforms6.
But that’s just one of the two tiny problems!

How much semantics do we even have?
See, we’ve been using “Customer Lifetime Value” as our example above. We already saw that across different solutions, the metric can have different definitions and different calculation logic.
But what if we don’t even agree on what a “Customer” is?
Whose lifetime value is being calculated? The metric definition code block gives us some ideas perhaps. But if there’s another metric somewhere called “Customer Conversion Rate”, do we know if it measures the same customers? Are trial subscriptions counted? How about former customers? Or prospects?
Turns out, most “Semantic Layer” technologies don’t care.
Sure, you can add descriptions to fields, and metrics, and views, and tables, and schemas, and “explores” (whatever they are), and dashboards, and workspaces, and and and…
But those are all technical objects that may or may not contain information about Customers. Where is the actual concept of “Customer” defined? Or how “Customer” relates to other concepts, like “Order” or “Delivery”, so that we (or our AI agent) could find out what else we know about them? Nope, not part of the “Semantic Layer”, it seems.
Considering these two issues - solution-level siloes and descriptions being applied primarily to technical objects - it’s actually quite remarkable how little semantics there is in the “Semantic Layer”.
The Content of the Context

You might want to check out my earlier article on what the semantical information really is that we need to manage!
Having said all that, please believe me when I tell you that I don’t consider the “Semantic Layer” technologies to be useless or bad. They’re playing an important role in making the data we have more understandable to humans and AI alike7. It’s just that we need more - it’s simply not enough to put a label on a data object, so that we understand it when we look at it.
Even when more advanced capabilities for semantics management are sometimes offered by some of these technologies, they fail to apply consistently across platform boundaries, or even to enforce consistency between different solutions within the same platform. Some of that is due to lack of understanding or vision on the users’ side, but the brutal truth is that the “Semantic Layer” technologies were never intended to really manage semantics. They were, and are, meant for attaching labels to technical objects, without much interest or capability in managing your inventory of labels, as it were.
Where do we go from here?
Semantics as it’s been implemented in the current crop of “Semantic Layer” tooling is not enough. We need cross-platform semantics to help us find the right data objects in the first place, to help us understand which data objects we should be looking at, and to help us decide between two similar-looking data objects.
This means separating semantics from the data it describes, and managing it on its own, holistically, across platforms. We also need to leave behind the notion of semantics being applied to data at the BI stage, the point where we want to start building dashboards: in the age of AI agents, semantics needs to be applied everywhere.
“Semantic Architecture”, for want of a better word, is an emerging area where very few best practices or practical implementations exist8. We have well-established standards for storing and organizing the semantical information itself in the form of the web ontology stack and the related processes and methods; but the big picture of how these methods and technologies should be applied to and connected with the rest of our data architecture is only now being formed.
In the next article on Common Sense Data, I hope to offer my 2 eurocents on what I think is developing in this area. See you there - until then, thank you for reading and cheerio!
“please describe CLV trend for DACH customers in iambic pentameter”
I am using quotations here in an ironic fashion, the reason for which will hopefully become clear as you read along. Just imagine me doing the Dr. Evil air quotes from Austin Powers every time!
It DOESN’T. There’s no law anywhere that says that your data solution in the “Semantic Layer” needs to be a dimensional model. It’s often practical and handy to have a dimensional model there, but it’s by no means the only possible choice.
This syntax is LookML. Or maybe it is something resembling LookML. It could also be entirely wrong. The syntax (or the specific technology platform) is not the point, dear reader.
This is (perhaps) a snippet of DAX. I have to admit I’ve never quite figured out DAX; it seems to actively resist my attempts at understanding it, like some kind of a hyper-conscious higher-dimensional creature, laughing at a mere mortal, perhaps not entirely unlike Cthulhu. CALCULATHULHU? Anyways, the combination of doing less hands-on PowerBI work over time and having LLMs available to translate it to mortal tongues means it doesn’t bother me as much anymore (although you can never be fully released of such existential horror).
And even within a single platform, having the ability to define reusable semantics does not mean that the ability will be actually used. Weak governance and output-focused teams often mean that solution-level siloes are created even where they could technically be avoided.
Although, as Keith Belanger (whom I greatly respect) once pointed out to me, it does feel a bit like the whole debacle about semantic layers could’ve been avoided if people had just bothered to do proper data modeling & metadata management in the underlying Data Warehouse layer…
Maybe some FAANG-level players have stuff figured out, but that’s neither here nor there for the remaining 95% of us.
The organizations that have had the discipline to continue having intentional data modeling, or better the blast from the past role of data modeler (lucky enough to prove value to have data modeling as part of your SDLC), are so far ahead with data meaning and context. The data modeler/modeling tools collected the terms and definitions in the boring 'data dictionary'. As well as relationships, domains, data types, technical and business names. The data model metadata perfect for AI ingestion to understand 'context'. Term has 1:M to attributes, attributes 1:M to tables, tables have 1:M to databases... reusability and relationships. Great food for AI. And frankly, what is needed for a 'Semantic Layer'. Can 'AI' give us the ROI to have a data modeling renaissance? As using AI with Data Modeling, but it being a driver for the magical semantic layer.
Can I add my favorite one. we updated the object but never updated the description to reflect the update <eyeroll!!!>