
Notes from Data Mesh Live 2026
Takeaways & feelings from Antwerp

One of my favourite conferences (besides Helsinki Data Week, of course1) is Data Mesh Live in Antwerp, Belgium. The content, the people, the atmosphere, and the slick practical arrangements all “mesh” together in what can only be described as a sum far larger than its parts. This year’s event now done and dusted, I though I’d write a few words about ideas that stuck with me. It’s all relatively fresh in my mind, you see, as I’m writing these words onboard a plane home!2
The conference
There’s something intimate about Data Mesh Live. Perhaps it’s the size: one venue, one track (plus some workshops), and maybe 100-150 participants makes for a nicely contained and focused event, compared to many of those huge data industry hullabaloos with thousands of people and dozens of vendors out-marketing each other.
But I suspect the thing that makes DML (which is an initialism they probably don’t officially use, but for brevity’s sake I will!) such a pleasure to attend is that they’ve understood what most of us really need: new ideas, sure, but also ample opportunity to meet our peers and discuss those ideas. I’ve always considered socializing to be the most enjoyable part of a good conference3, and somehow they’ve managed to build the program with an excellent balance between sit-down-and-listen content and those serendipitous moments around the coffee (or, in my case, tea) machine where you shake hands with someone new and let the discussion take you away in unexpected directions. It’s not an easy feat by any means, and with Helsinki Data Week we’re getting there but still figuring some things out. Data Day Texas (now sadly discontinued) had a similar, somewhat magical atmosphere.

The content is, of course, a big reason people come to these events, and at DML 2026 it was once again stellar. This year, I had the privilege to present there as well - a source of much pride for me personally, considering the caliber of speakers they had on stage! When I was attending last year, I took away content and concepts that I have been coming back to ever since. I suspect the same is going to happen this time; and with that in mind, I want to share here some of these thoughts and learnings.
What follows is going to be my personal take on some of the themes I found thought-provoking and particularly timely. I can’t possibly list all of them, so packed were these two days in Antwerp, but consider this a sample selection!4
It’s not just the AI, it’s what’s underneath the AI
I mean of course it’s all about AI these days. But I find it very refreshing that the discourse has moved from “oh look at what AI can do” to “here’s how you build a solid data foundation for AI”. AI is a data consumer with particular needs, and surprise surprise - good data architecture practices make everything easier for AI as well.
In the opening keynote, the legendary Neal Ford talked about the “architectural quantum”. Zhamak Dehghani famously described the data product as the “architectural quantum” for analytics: the smallest piece from which everything is built, which sets the overall granularity level for your data architecture (i.e. you don’t go smaller than that in governance or management of your assets)5. Neal’s talk covered the history of this thinking, as well as its portential future. A microservice is the architectural quantum for operational side, a data product is the quantum for analytics, so what is then the quantum for the agentic age? Now, I’m a data guy, not a software architect, so some concepts here were a bit challenging to follow occasionally, but I do find it interesting to consider that a domain could be made of three kinds of quanta: microservices, data products, and agents, all with their wrappers and input/output ports, and all interconnected. It feels symmetrical somehow, and I like that!
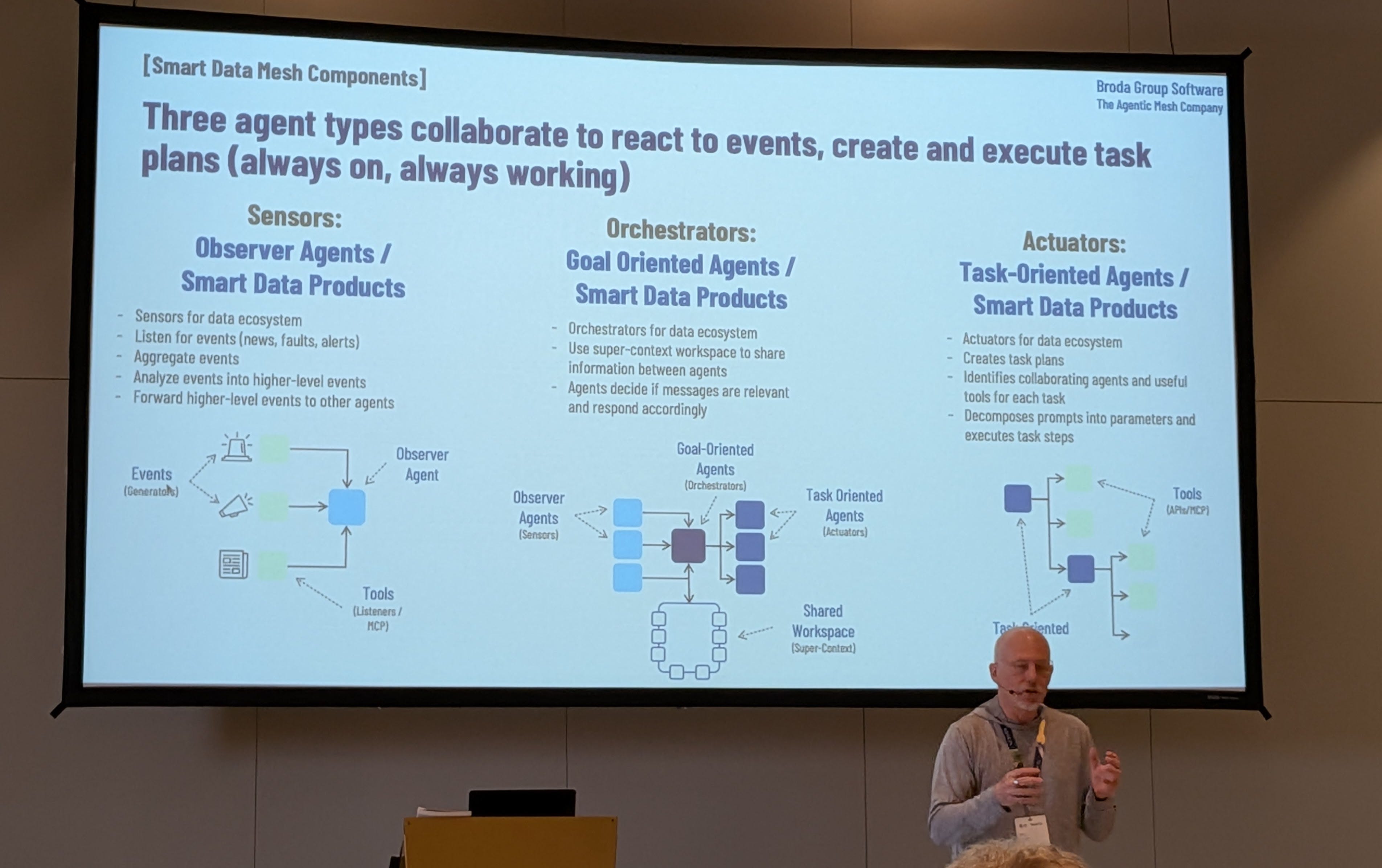
Another really interesting talk focusing on AI and agents was by Eric Broda. Eric is looking into agentic ecosystems and the guardrails and governance needed in this new type of “agentic mesh”. He also posed a question that sparked many coffee discussions later: what if an agent lives inside the data product? What would this “smart data product” look like, and what would the architecture around such products look like? All this made my brain properly buzz! I also had the opportunity to have some wonderful discussions with Eric off-stage around the topics of smart data products, semantics, “minimum viable context” and all that - there’s a lot there to think about, and I’m hoping to continue these discussions in the future!
On day 2, the event’s host Tom de Wolf did a wonderful talk on platform maturity. I took lots of photos of the maturity model he presented, and will certainly be returning to those many times! Personally I’ve found that in mesh-y setups, the organization’s technological success depends entirely on their capability for platform thinking (as opposed to just buying a bunch of tools and letting everyone do whatever they want), and far less on the capabilities of individual tools. Tom has a simple but systematic approach to analyzing the current state of the “platformness” of the platform - not a collection of tools, but an actual self-service where Developer Experience is explicitly a goal. Tom’s talk also worked really well together with Andrew Jones’s talk on platform engineering.6 Real autonomy and efficiency is built with easy-to-use services provided from a well-defined toolbox. Free-for-all looks “agile” but in reality it’s just a lot of noise and nonsense, and eventually leads to an impossible spaghetti.
Context is king (And semantics is duke? countess? marquis?)
I did my talk on semantics and context on the first day, and used the line “context is king” on a slide somewhere. I can’t remember where I read that phrase first, but it’s been around for a while now (and my buddy Stan runs events under that title, too). I just want to point this out so that no-one thinks I came up with it!7
It’s true though: context is what AI needs to figure out how your organization works. Without context, you get the same average responses that everyone else gets, and there’s no differentiation in that8.
My argument was familiar to readers of this blog: because we need shared context, not solution-level siloes, we must separate semantics from the data and govern it as a layer of its own. This is the idea of the Data Plane (where actual data resides) and the Knowledge Plane (where semantics resides), and the semantic linking between those. It was last year’s Data Mesh Live and Andrea Gioia’s presentation there that crystallized the concept for me.

This year we had many voices joining the context choir. Saskia Untiet-Kepp pointed out that “trustworthy AI” can only exist as a sum of LLM’s, semantics, and well-governed data products. Kiran Prakash showed how the implementation of the data products themselves becomes almost a trivial task, easily automated, once you have enough context.

Andrea Gioia was there as well, of course, and together with Giorgio Tavecchia they presented a really interesting thesis on physical modeling. In short, they basically said it’s obviously important to have your conceptual model in place (yes, this was pure catnip for me), but that because the semantic linking is so important, your physical model should be as close to the conceptual model as possible. Therefore, they concluded that middle-level aggregate data products should be modeled as Data Vault structures, and consumer-facing data products as Unified Star Schemas! This is a very strong statement, and to be honest I need to digest this a bit more before I give my opinion on it, but I can certainly see the merit in making the semantic linking simple.
The spiciest context take was delivered by Ole Olesen-Bagneux in the last presentation of the conference. It’s difficult to believe anyone else in the world could’ve done this: he flew in to a Data Mesh conference, grabbed Zhamak’s book (the Holy Bible of all Mesh-heads), read quotes of the book on stage, and proceeded to tear down Zhamak’s arguments on metadata one by one. And he made a damn good show out of it. Ole has this rare capability of appearing completely serious and very funny at the same time, all while delivering razor-sharp thinking9.

Ole had some good points. In the original Mesh book, Zhamak considered metadata to be completely contained within a data product: the product takes care of all its metadata, and serves this metadata alongside its actual data. No extra layers, no catalogs, no metadata management per se. This is a very much engineering-focused view. But the reality of metadata is far wider than what a single data product can express! Ole is absolutely right with his Meta Grid concept, which explains the reality of organizations as a “mesh” of systems and teams who all have their own visibility and understanding of the IT landscape. IT service management, Enterprise Architecture, endpoint management, document management, infosec… All of these have their own metadata which can’t be contained within a data product. Instead, Ole is calling for metadata products that specifically exist to serve metadata across the domain boundaries of the Meta Grid, just like regular data products serve data across the domain boundaries of the Data Mesh. There’s that symmetry again - I like it!
It all comes down to people
Data Mesh is a socio-technical framework. In the implementations I’ve seen and participated in, it is this social and organizational aspect that causes the most headache - but also delivers the most value when you get it right.
I’ve often complained (and will continue to complain) about the excessive technology focus in the data industry: it’s like we barely even see the people who the tech is for. Data Mesh is one of the rare frameworks where this side gets its fair share of attention. However, it must be said that the socio-part was in a rather small role in this year’s DML! Perhaps it is because we like to think more about AI users than those pesky human users?
Luckily, we had Amy Raygada! Amy’s approach is strongly people-first, and I heartily agree with her (I was nodding furiously throughout her talk). She spoke about buy-in, internal selling, and honest competence evaluation before jumping head-first into data platforms. Amy’s talk was a breath of fresh air amidst all the technology and context management. Success with a federated model depends so much on organizational and human factors that it simply cannot be overstated.10

But as I mentioned in the beginning of this article, a large part of the DML magic comes from the people participating in it. I had so many cool discussions; people came to me after my talk, even on the day after, and had wonderful questions and comments. And I met many old friends, and made new friends too!

It really was a wonderful event altogether. My sincerest gratitude to the organizers for letting me on stage in Antwerp, and for putting together such a delight of an event! And thank you to everyone who came to talk, who shared a cup of tea (or beers, or cocktails, depending on occasion) with me, and who made this so much fun.

I’ll be joining next year for sure! In the meantime, if you were there in Antwerp and there was a discussion we couldn’t finish or a question you still wanted to ask, please don’t hesitate to throw me a message here or on LinkedIn - and come check out our event in Helsinki in October!
Until next time - cheerio!
If you didn’t know, Helsinki Data Week is a week-long festival of all things data & AI that Säde Haveri, Antti Rask, Eevamaija Virtanen, and myself founded in 2023. It’s going to happen for the third time in October 2026, and you should certainly come!
Seems that I get most of my writing done in planes nowadays. Perhaps the trick to keep up with my writing schedule would be to travel more!
Though I must admit that as an introvert, it takes its toll! But being tired and happy is not a bad state to find yourself in.
And naturally, all misunderstandings and misrememberings are my fault and mine alone (although that bottle of Rochefort 10 could potentially be blamed for cutting a few synapses between neurons that should have retained important data architecture learnings).
By the way, that link to one of Zhamak’s original articles takes you to Martin Fowler’s website, and Martin Fowler was also there in Antwerp! Data Mesh Live is a sort of a sidecar conference for Domain-Driven Design Europe, happening at the same time, where Martin was presenting. We were in the same group walking to the speakers’ dinner, but I felt momentarily too shy to approach and shake his hand. Dammit! He had a cool hat, too.
I’m eternally grateful to Andrew for sparring with me on my presentation before the conference. He had some excellent feedback on my early draft, without which my presentation certainly wouldn’t have been received as well as it was. Thanks Andrew!
Eric was quick to add the phrase into his presentation later in the day as a quote from me and Shane, but honestly, it was just something we had been talking about in the morning, not an original invention!
As my friend and HDW-colleague Säde pointed out in a podcast episode we did earlier in the year: if your business is so generic that any LLM can understand all its nuances immediately with no extra help, then you won’t have a business for long.
Also, Ole posted on LinkedIn before the conference that this would be his last talk on Meta Grid. I don’t know about that - the concept is too real to forget! But it is a nice thought that his first Meta Grid talk was at Helsinki Data Week 2024, and now I was there to witness (perhaps) the last one.
Amy is also going to speak at Helsinki Data Week this year! Just sayin’.