
Conceptual Modeling: Thinking Beyond Solution Design
Semantics discovery & the big picture

In my last post on this Substack, I wrote about the Conceptual-Logical-Physical data modeling triptych. In it, I (rather forcibly) argued that data modeling is an important design activity. Which it indeed is… but that’s not all.
Conceptual, Logical, Physical - the Truth(*) About Data Models

Well, here we go - we’re finally broaching the subject on data modeling on this Substack. It was always inevitable: data modeling is my Thing, and has been for at least the last dozen-or-so years. This is going to be a bit longer long-form piece, but that is to be expected when it comes to data models!
See, one of the worst misunderstandings regarding data modeling is that it’s only about solution design. Far from it - I find that some of the most important value from data modeling is created when we use conceptual data modeling for other purposes. In this post, we’ll explore what those purposes are and why data modeling makes sense even when no-one’s trying to build anything.
Conceptual modeling as semantics discovery
Let’s recap a bit of what I wrote about conceptual modeling last time. I pointed out that conceptual modeling is all about understanding the business, and we should use conceptual models to
understand and document the business entities that exist in the real life, and map how they are connected to each other.
This I wrote in the context of design: we can’t deliver a meaningful and impactful data solution, if we haven’t figured out what the data is about first.
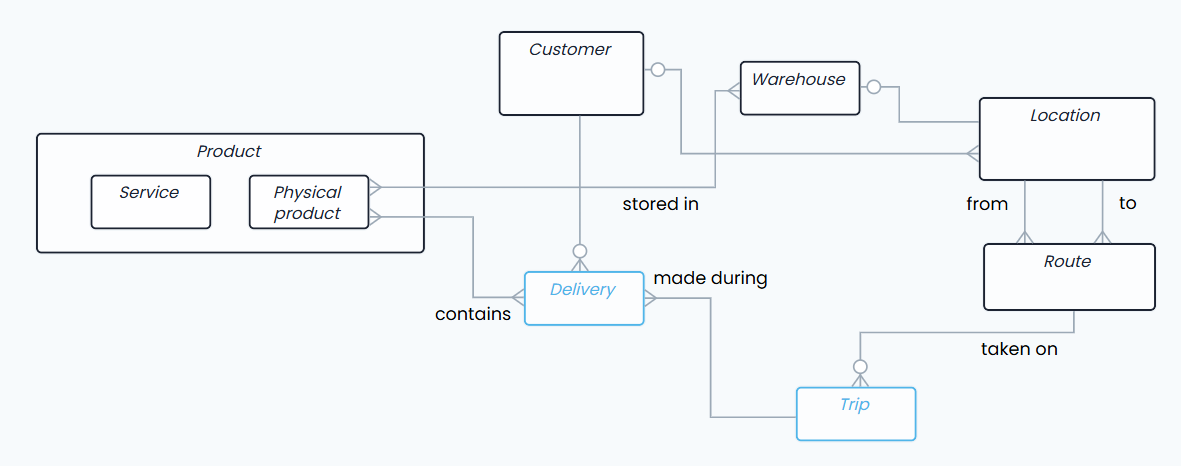
But I also pointed out that conceptual data models, when done correctly, are infinitely reusable. That is to say, the business entities and their relations are true as long as the business itself remains the same - the conceptual model is not only technology-agnostic, but also solution-agnostic1.
So what are we modeling when we’re doing conceptual modeling?
When we add an entity on the canvas, we’re saying that a thing exists. We’re (hopefully) also defining what we mean by that thing; the model often tells us how “Customer” and “Prospect” are different. When we add a relationship between two entities, we’re saying that there’s a connection between these things, and we (hopefully) give it a label describing the nature of the association (e.g. “Customer receives a Delivery”). We’re modeling knowledge about the world - we’re discovering and documenting semantics.
And don’t be fooled now by all the vendor talk about “semantic layers” and “semantic models”! In today’s general tech-parlance, those two terms most often refer to specific kinds of technological objects2. No, what I’m talking here is the actual semantic content: we’re modeling the meaning of words.
In fact, a conceptual model should be something you can read out loud3. This is because it’s made of entities (nouns) taking the role of subjects and objects, and relationships (verbs) forming the predicates - and hold on, what’s that? Sounds familiar?
Subject-predicate-object is the basic structure of an ontology. Now, you would do well to read Jessica Talisman’s writings on the “Ontology Pipeline”: start here, for example. We need ontologies to give our data context, and ontologies are what we get when we properly define our entities and relationships. I won’t go into too many details in this post right now, but the key thing to understand here is that conceptual modeling is ontology work. And because these little ontological nuggets are so valuable, we need to ensure we catch them when they are discovered. That’s how we build up our semantics.
Two paths, one less taken
In effect, then, we have two objectives for a conceptual model:
It is the starting point of good data design, eventually leading to a solution being created. This I call the DESIGN path.
It is a means to discover and document semantics, eventually leading to an ontology being defined. This I call the DISCOVERY path.
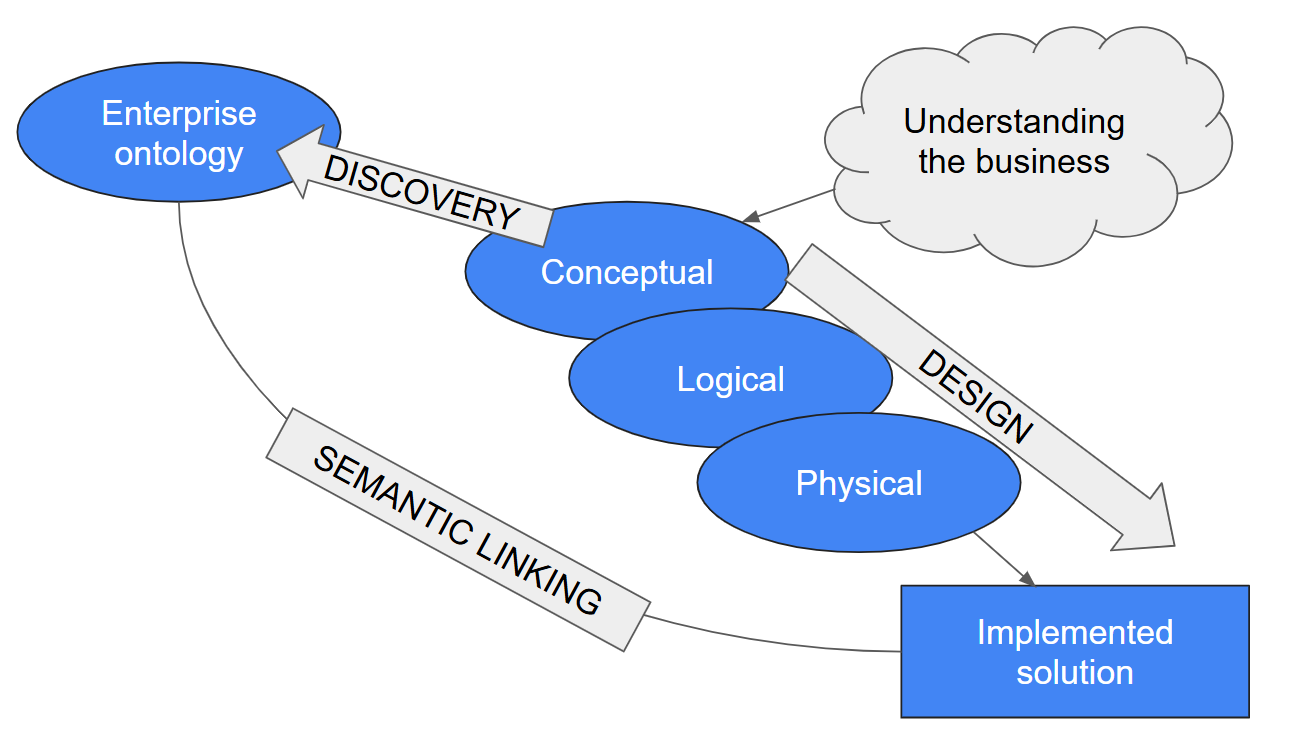
Both paths start from the same point: we’re looking at the “slice of reality” that is our scope within the business, and we try to make sense of it. We create a conceptual model that describes the entities and relationships4, and we use that not only to design a single solution, but also to persistently document the knowledge about the real-world entities and relationships that was captured, so that we can reuse it later. And if we do it smartly enough, this makes it very straightforward to semantically link the solution and its technical data objects with the ontology and its semantical objects - this linking is what then delivers the much-sought-after context around our data. After all, both the solution design and the relevant parts of the ontology are based on the same conceptual models!
Now, if you happen to have read my two earlier articles about the “Big Problem” and the “Small Problem”, you might recognize a pattern here. Indeed, we’re looking at the same enterprise-level vs. solution-level dichotomy here.

We need both levels! As I argued in those posts, we can only succeed as an organization if we can solve both problems at the same time: ensure that an individual solution succeeds and delivers value, and ensure that success can be repeated across all solutions everywhere in the organization.
However: most people see data modeling only on the DESIGN path5. This is yet another manifestation of the solution-level myopia that many data organizations suffer from - we’re simply so focused on the tasks at hand that our thinking is reduced to the tactical.
We can, and should, think more strategically. Conceptual data modeling is the point where we have both paths available to us, towards the solution level and towards the enterprise level.
But there’s something here that I must point out: we do not want to walk the enterprise path into a minefield.
The (well-deserved) death of the Enterprise Data Model
That minefield is the EDM, the Enterprise Data Model6.
See, back in the day, it was believed that if we just drew a single, all-encompassing data model of the entire enterprise, then everything would become super easy and there would be no integration problems or data quality issues and you could basically automate everything.
There was just one, slight problem: drawing that model turned out to be impossible.
I remember a story I heard (possibly from Steve Hoberman?) about an idealistic young data modeler being hired into an Enterprise Data Modeling team to map the entire known world like some modern-day Amerigo Vespucci. A few years later the initiative was eventually scrapped as it had not produced anything useful despite producing inordinate amounts of stuff.
You still encounter top-down EDM initiatives7 occasionally, usually driven by some rather old-fashioned Enterprise Architecture thinking. But these are becoming increasingly rare, and for a bunch of good reasons:
It’s really difficult to model everything. It takes a lot of time and effort and you need good data modeling skills to be able to model and connect different areas of business in a consistent fashion.
The level of detail at which most EDMs were traditionally done was way too much. Defining all the hundreds of keys and other attributes in what was effectively a mega-scale logical model8 took insane effort.
Most of these models were one-off exercises. Beyond a vague reference to “continuous EA practices”, maintenance processes were usually not planned and/or resourced. The models started to rot even before they got to version 1.0.
As a result of all the following, the EDMs were hardly ever really used in actual projects. Maybe at some early stage of the Official Gate Process, a weary Enterprise Architect would have a look at your system documentation and note that the planned solution “has a reasonable fit” with the EDM. But little to no actual impact was often seen.
So organizations, for the most part, stopped doing Enterprise Data Modeling. Which was kind of sad, because that killed off a lot of enterprise-level thinking relating to data models, and a lot of really excellent data modelers then simply retired without passing on their skills, but also it was totally necessary, because a lot of that work was, to put it bluntly, pointless.
I personally don’t believe in a single, all-encompassing Enterprise Data Model at the level of detail it is usually attempted. I don’t think it’s possible to create such a model to begin with: the parts you modeled first will require changes before you get to the end. Nor is it possible to keep it up to date.
So why, then, am I advocating for an enterprise-level path for conceptual modeling? Seems contradictory!
Building the big picture bottom-up: domain-driven design (and discovery)
I wrote above that I don’t believe in a single Enterprise Data Model. I do, however, believe in multiple models forming a big-picture view of the enterprise.
If a conceptual model describes a slice of reality, and we have a bunch of conceptual models defining different slices, we should be able to put those slices back together to form a reasonable approximation of the entire pie. Sure, there will be weird overlaps, and there will be (despite our best efforts) parts where people have a different understanding of the same concept, but that’s going to happen in any case. Just like you should eat an elephant one bite at a time, you should… rebuild… the pie? One slice at a time? Look, I don’t know either, the metaphor might have got out of hand but the point stands. From smaller pieces, a larger thing emerges - not as a forced canonical construct, but as a living object.
But what is the larger thing? The entire pie, or, uh, the whole elephant? Well, perhaps not.
I work mainly with larger enterprises. While a smaller organization might be well able to construct this big picture as a single view, for most organizations it’s a difficult proposition. My dear friend John Giles has written about the “Data Town Plan” - in effect, an ultra-high level conceptual data model of the entire enterprise - in his book “The Data Elephant in the Board Room”. 9

John’s argument is that the high-level enterprise view can indeed be constructed, if the level of abstraction is chosen properly, and repeating patterns are identified and utilized to speed up the work. The patterns are like my “slices” - it is from these smaller pieces that the Data Town Plan emerges.
While I agree with John’s view in general, I sometimes struggle to find an enterprise-wide agreement and understanding on semantics. In effect, we can usually agree that a certain “thing” exists and it’s related to other “things”, but we can’t agree on what to call it. Additionally, it seems that in practice many organizations have rather natural boundaries around specific areas of the overall, uh, knowledge pie: the people in Finance know their stuff, the people in operations know about logistics, etc. etc.
Luckily, that pattern is well known in the world of software development. Those are domains.
Eric Evans is of course the OG big name in Domain-Driven Design, but I have to be honest: I haven’t read his book. My thinking on domains was particularly heavily influenced by Zhamak Dehghani’s “Data Mesh: Delivering Data-Driven Value at Scale”, which is the original bible of Data Mesh, and all the writing and thinking around it.
The key is that there are natural “areas” of business that can be defined in a way that is internally consistent within that area’s boundaries, and if we choose these domains well and understand their cross-domain connections, we’ll have an easier time with the full big picture.
I don’t want to go too deeply into the intricacies of Data Mesh10. Instead, let’s cut it short, and allow me propose the following conclusions:
We can, and we should, consolidate the semantic information we discover from solution-level work.
We should plan this consolidation process so that it receives inputs from all the solution-level design work we do. It should be a continuous, living process - not a single top-down initiative.
The scope of this consolidation should be the domain instead of the entire enterprise.
We should strive to understand how the domains are connected - in effect, which concepts and relationships reach across domain boundaries - and pay special attention to those areas.
Thus, our “Enteprise Data Model” (or indeed, the Enterprise Ontology) is not a single diagram, but a collection of interlinked domain-specific models, which in turn are consolidated from solution-level discovery work.
Getting the good spiral spiraling
Once we start having even small parts of that Enterprise Ontology in place, we can feed back semantical information from the enterprise level to the solution-level design work. Oh you’re working with logistics? Here’s the current domain model, use that as the basis of your work! Reuse structures, connect solutions to existing semantics…
This creates a self-reinforcing loop where the conceptual modeling we do for the DESIGN path feeds the enterprise-level semantic repository via the DISCOVERY path, and the gathering of semantic information on the enterprise level makes the next DESIGN path faster and more straightforward.
This is exactly what I described in my previous article about the feedback loops between enterprise and solution levels, but in the context of semantics and data models.
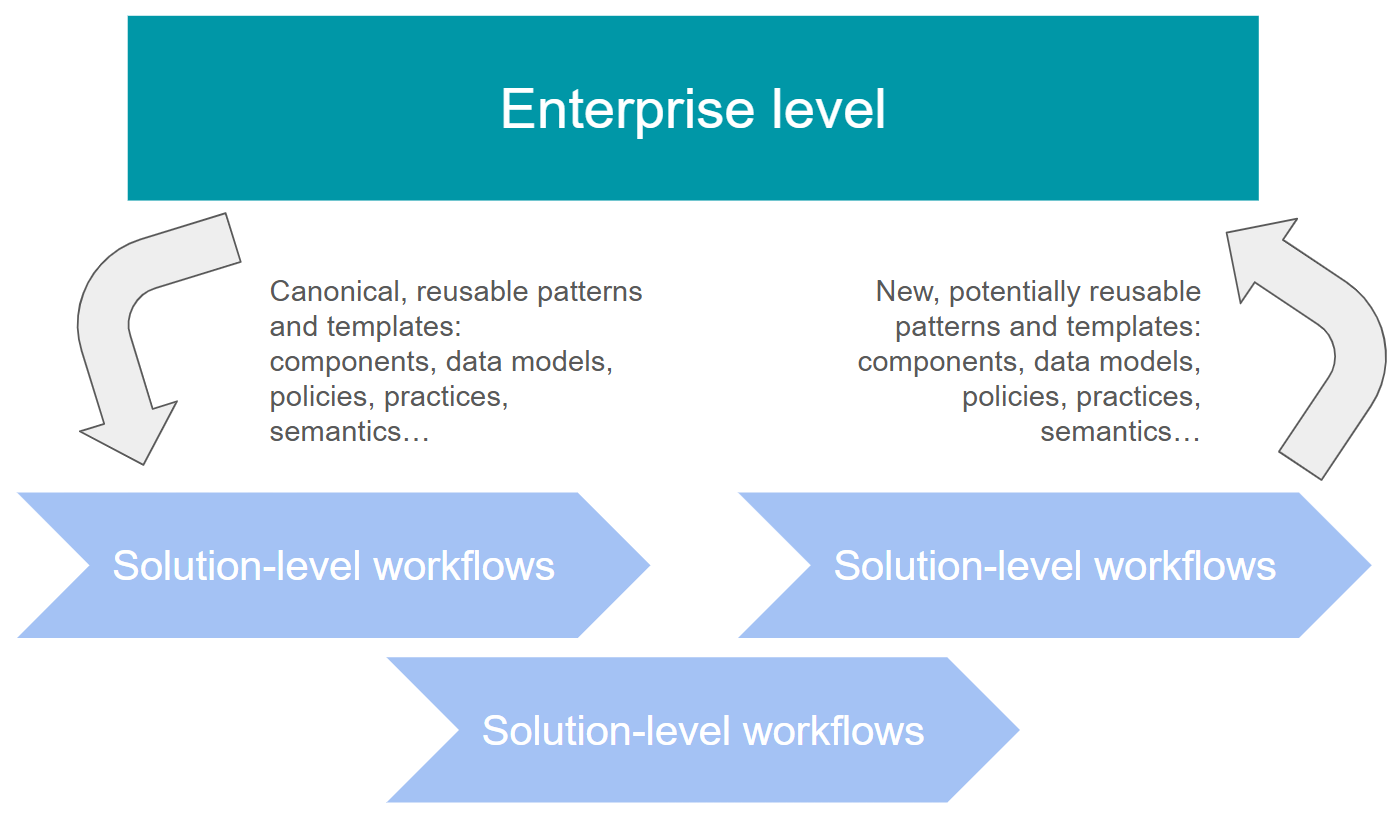
You want that loop rolling. The benefits are immense. For semantics, the way to do this is to recognize both paths - DESIGN and DISCOVERY - and to take all possible advantage of conceptual modeling; not as a separate, top-down initiative, but as a living and breathing part of every project.
Thank you for reading this! If you have any questions or comments, please reach out. And if you found this inspiring or interesting, please consider sharing and/or subscribing to Common Sense Data!
Until next time - cheerio!
Though you can make a point about the scope of the model often being solution-dependent. But this still means that the entities and relations within that scope are globally valid.
In general, I find that when people say “semantic model”, they mean “a dataset built inside a specific technology that has a shape somewhat resembling a dimensional model, and that has some descriptions added for its tables and columns”. The fact that there is so little semantical information in the semantic model, and that the word “semantic” seems to have lost nearly all its meaning, is ironic on many levels and would be highly amusing were it not such a source of frustration.
Literally reading a conceptual model out loud is an excellent practice and you should do it every time you either create or present a model.
And attributes, if you wish - several people pointed out after my previous article that attributes can and should be an important part of a conceptual model. I fully understand this viewpoint. My emphasis on entities and relationships but not attributes at the conceptual level is merely a result of practical experience: people get stuck on attributes. And I don’t want to have people stuck in the weeds if we haven’t even agreed on the basic concepts yet. But more on this and other practical methods of modeling and facilitating of modeling later, I promise!
If they consider it at all, that is!
“EDM” can of course also refer to other things, like Enterprise Data Management, or Electronic Dance Music. It amuses me to swap these definitions around in my head at inappropriate times and to imagine David Guetta and Skrillex sitting in the EDM Council.
Hehe
Refer to my previous article on the differences between conceptual and logical modeling.
John also has two more books with elephantine titles that are really good. I’m not aware of any pie-related work he might have published.
I suppose I will at some point…